Невронни мрежи (ANN) — принципи, обучение и приложение в ИИ
Невронни мрежи (ANN): принципи, методи за обучение и реални приложения в ИИ — от основи до дълбоко обучение, примери и практически решения.
Невронната мрежа (наричана също ANN или изкуствена невронна мрежа) е вид компютърен софтуер, вдъхновен от биологичните неврони. Биологичните мозъци решават сложни задачи чрез голям брой взаимодействащи клетки, при което всеки неврон допринася само за малка част от крайния резултат. По подобен начин изкуствените невронни мрежи съставят система от прости изчислителни елементи (възли), които заедно моделират и решават сложни проблеми. Това е един от основните подходи за създаване на изкуствено интелигентни програми.
Галерия с изображения
6 Изображения




Основни принципи
В основата на невронната мрежа стои модел на изкуствен неврон, който прилага линейна комбинация от входните стойности, умножени по тегла, добавя отклонение (bias) и преминава резултата през нелинейна функция (активационна функция). Ключови компоненти:
- Възли и слоеве: входен слой, един или повече скрити слоеве и изходен слой;
- Тегла и отклонения: параметрите, които мрежата "учи";
- Активационни функции: например ReLU, sigmoid, tanh — те внасят нелинейност;
- Функция на загуба: мярка за разликата между предсказани и целеви стойности (например MSE, cross-entropy);
- Оптимизатори: алгоритми като стохастичен градиентен спуск (SGD), Adam, RMSprop, които актуализират теглата, за да минимизират загубата.
Архитектури
Съществуват множество архитектури, адаптирани за различни задачи:
- Препредаващи (Feedforward) мрежи: базовите невронни мрежи за регресия и класификация;
- Свертъчни невронни мрежи (CNN): особено подходящи за обработка на изображения и пространствени данни;
- Рекурентни мрежи (RNN), LSTM, GRU: обработват последователности и времеви редове (език, говор);
- Трансформъри: съвременен стандарт в обработката на естествен език и генеративни модели, благодарение на механизма "self-attention".
Обучение и оптимизация
Невронните мрежи са пример за машинно обучение, при което моделът се променя чрез процес на обучение. Обучението може да бъде:
- Наблюдавано (supervised): с етикетирани примери (например изображения с етикети);
- Ненаблюдавано (unsupervised): при търсене на структури в неетицирани данни (напр. клъстеризация, автоенкодери);
- Подсилващо (reinforcement): агент учи чрез награди и наказания от средата.
Обичайният механизъм за обучение на невронни мрежи е обратно разпространение на грешката (backpropagation) с оптимизатор като градиентен спуск. Хиперпараметри като скорост на учене, размер на батча, брой епохи и структура на мрежата влияят силно на резултатите.
Една невронна мрежа може да бъде подобрявана с всеки пример, но колкото по-голяма е мрежата, толкова повече примери са ѝ необходими, за да работи добре — в случая на дълбокото обучение често са нужни милиони или милиарди примери. Освен данни, успешното обучение изисква изчислителни ресурси (GPU/TPU), техники за нормализация, регуляризация (dropout, weight decay) и внимателен подбор на данните.
Приложения
Невронните мрежи се използват широко в много области:
- Компютърно зрение: откриване на обекти, сегментация, разпознаване на лица;
- Обработка на естествен език: машинен превод, анализ на тоналността, чат-ботове;
- Генеративни модели: синтез на изображения, текст и звук (GAN, VAE, трансформъри);
- Медицина: диагностика от изображения, анализ на биомаркери;
- Автономни системи: самоуправляващи се автомобили и роботи;
- Препоръчителни системи и финансови приложения.
Предизвикателства и етика
Въпреки напредъка, невронните мрежи имат ограничения и водят до важни въпроси:
- Необяснимост (interpretability): сложните модели често са "черни кутии";
- Пристрастия: модели, обучени на несъвършени данни, могат да възпроизвеждат и усилват социални пристрастия;
- Злонамерени атаки: adversarial примери могат да подвеждат моделите;
- Енергийна ефективност: тренирането на големи модели е енергоемко и скъпо;
- Поверителност: използване на чувствителни данни налага мерки за защита (диференциална приватност, федерално обучение).
Практически насоки
- Започнете с прост модел и малък набор от функции; усложнявайте само при нужда.
- Почистете и нормализирайте данните; използвайте техники за увеличаване (data augmentation) при ограничени данни.
- Разделяйте данните на обучаващ, валидационен и тестов набор и следете за overfitting.
- Използвайте трансферно учене при малки набори от данни — предварително обучени модели често дават добри резултати с минимално фино настройване.
- Експериментирайте с различни архитектури и оптимизатори, но водете отчет за хиперпараметрите и резултатите.
Невронните мрежи продължават да бъдат активно изследвано и внедряващо се поле, съчетаващо теория, алгоритми и инженерство. С правилни данни, инфраструктура и отговорен подход те могат да донесат значителни ползи в много области, като същевременно изискват внимание към етичните и практическите предизвикателства.
Преглед
Невронната мрежа моделира мрежа от неврони, подобна на тази в човешкия мозък. Всеки неврон извършва прости математически операции: получава данни от други неврони, модифицира ги и ги изпраща на други неврони. Невроните са разположени в "слоеве": неврон от даден слой получава данни от неврони от други слоеве, модифицира ги и ги изпраща на неврони от други слоеве. Невронната мрежа е съставена от един или повече слоеве.
Първият слой се нарича "входен слой" и получава данни от външния свят (например: изображение или текст). Последният слой се нарича "изходен слой". Данните от невроните в изходния слой се прочитат и се използват като изход на мрежата. Другите слоеве се наричат "скрити слоеве".
В една обикновена мрежа с пренасочване данните, които невроните обработват, са числа. Всеки неврон прави претеглена сума от стойността на невроните от предишния слой (  в уравнението по-долу). След това към нея се добавя постоянна стойност (наречена "отклонение"). Накрая към тази стойност се прилага математическа функция, наречена "функция на активиране". Функцията за активиране обикновено е функция, която връща стойност между 0 и 1, например tanh. Резултатът от функцията за активиране (
в уравнението по-долу). След това към нея се добавя постоянна стойност (наречена "отклонение"). Накрая към тази стойност се прилага математическа функция, наречена "функция на активиране". Функцията за активиране обикновено е функция, която връща стойност между 0 и 1, например tanh. Резултатът от функцията за активиране (  в уравнението по-долу) след това се изпраща към невроните на следващия слой.
в уравнението по-долу) след това се изпраща към невроните на следващия слой.

За мрежата е дефинирана функция на загубите. Функцията за загуба се опитва да оцени колко добре се справя невронната мрежа с възложената ѝ задача. Накрая се прилага техника за оптимизация, за да се минимизира изходът на функцията на разходите чрез промяна на теглата и отклоненията на мрежата. Този процес се нарича обучение. Обучението се извършва на една малка стъпка в даден момент. След хиляди стъпки мрежата обикновено е в състояние да изпълнява доста добре възложената ѝ задача.
Пример
Разгледайте програма, която проверява дали даден човек е жив. Тя проверява две неща - пулса и дишането. Ако човекът има пулс или диша, програмата изписва "жив", а в противен случай - "мъртъв". В програма, която не се учи с течение на времето, това ще бъде записано по следния начин:
функция isAlive(pulse, breathing) { if(pulse || breathing) { return true; } else { return false; } }
Една много проста невронна мрежа, съставена само от един неврон, която решава един и същ проблем, ще изглежда така:
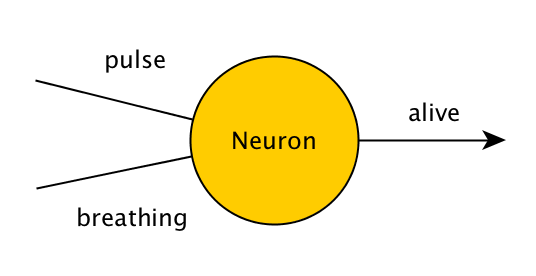
Стойностите на пулса, дишането и жив ще бъдат 0 или 1, което представлява лъжа и истина. Следователно, ако на този неврон се зададат стойностите (0,1), (1,0) или (1,1), той трябва да изведе 1, а ако му се зададе (0,0), той трябва да изведе 0. Невронът прави това, като прилага проста математическа операция към входа - той събира всички стойности, които са му били зададени, и след това добавя своя собствена скрита стойност, която се нарича "отклонение". В началото тази скрита стойност е случайна и я коригираме с течение на времето, ако невронът не ни дава желания изход.
Ако съберем заедно стойности като (1,1), може да получим числа, по-големи от 1, но ние искаме резултатът ни да бъде между 0 и 1! За да решим този проблем, можем да приложим функция, която ограничава действителния ни изход до 0 или 1, дори ако резултатът от математическите изчисления на неврона не е бил в рамките на този диапазон. При по-сложните невронни мрежи прилагаме функция (например сигмоид) към неврона, така че стойността му да бъде между 0 и 1 (например 0,66), и след това предаваме тази стойност на следващия неврон през целия път, докато не се нуждаем от нашия изход.
Методи на обучение
Невронната мрежа може да се учи по три начина: учене с наблюдение, учене без наблюдение и учене с подсилване. Всички тези методи работят чрез минимизиране или максимизиране на функция на разходите, но всеки от тях е по-добър при определени задачи.
Неотдавна изследователски екип от Университета на Хертфордшир, Великобритания, използва обучение с подсилване, за да накара хуманоидния робот iCub да се научи да произнася прости думи чрез бърборене.
Въпроси и отговори
В: Какво представлява невронната мрежа?
О: Невронната мрежа (наричана също ANN или изкуствена невронна мрежа) е вид компютърен софтуер, вдъхновен от биологичните неврони. Тя е съставена от клетки, които работят заедно, за да постигнат желания резултат, въпреки че всяка отделна клетка отговаря само за решаването на малка част от проблема.
Въпрос: Как се сравнява невронната мрежа с биологичните мозъци?
О: Биологичните мозъци са способни да решават трудни проблеми, но всеки неврон отговаря само за решаването на много малка част от проблема. По подобен начин невронната мрежа е съставена от клетки, които работят заедно, за да постигнат желания резултат, въпреки че всяка отделна клетка отговаря само за решаването на малка част от проблема.
Въпрос: Какъв тип програми могат да създават изкуствено интелигентни програми?
О: Невронните мрежи са пример за машинно обучение, при което програмата може да се променя, докато се учи да решава даден проблем.
Въпрос: Как може да се обучавате и подобрявате с всеки пример, за да използвате дълбоко обучение?
О: Невронната мрежа може да се обучава и подобрява с всеки пример, но колкото по-голяма е невронната мрежа, толкова повече примери са ѝ необходими, за да работи добре, като в случая на дълбокото обучение често са необходими милиони или милиарди примери.
Въпрос: Какво е необходимо, за да е успешно дълбокото обучение?
О: За да бъде успешно дълбокото обучение, са необходими милиони или милиарди примери в зависимост от това колко голяма е невронната мрежа.
В: Как машинното обучение се отнася към създаването на изкуствено интелигентни програми?
О: Машинното обучение е свързано със създаването на изкуствено интелигентни програми, защото позволява на програмите да се променят, когато се научат да решават проблеми.
Свързани статии
Автор
AlegsaOnline.com Невронни мрежи (ANN) — принципи, обучение и приложение в ИИ Leandro Alegsa
URL: https://bg.alegsaonline.com/art/6353
Източници
- newscientist.com : "Baby robot learns first words from human teacher"