Кеширане и алгоритми за изхвърляне: LRU, LFU, ARC, принципи и сравнение
Кеширане: сравнение на LRU, LFU, ARC — принципи, предимства, trade‑offs, hit rate и латентност. Практически насоки за избор и оптимизация на кеш-алгоритми.
Алгоритъмът на кеша е алгоритъм, използван за управление на кеш или група данни. Когато кешът е пълен, алгоритъмът решава кой елемент да бъде изтрит, за да се освободи място за нови данни. Думата hit rate (честота на попадане) описва колко често дадена заявка може да бъде обслужена от кеша; терминът латентност описва времето, необходимо за получаване на елемент от кеша. Алгоритмите за кеширане представляват компромис между максимизиране на hit rate и минимизиране на латентността и изискват баланс между използване на памет, CPU и сложност на имплементацията.
Галерия с изображения
7 Изображения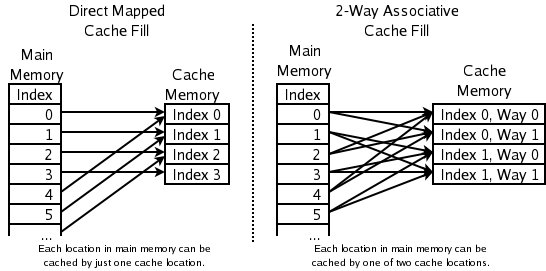



Основни принципи и оптимален стандарт
Най-ефективният алгоритъм за кеширане би бил такъв, който винаги изхвърля информацията, която няма да бъде необходима за най-дълъг период от време в бъдеще. Този идеален, теоретичен резултат се нарича оптимален алгоритъм на Белади или алгоритъм на ясновидеца. Тъй като в реални условия не можем да предвидим бъдещите заявки, алгоритъмът на Белади е недостижим в общия случай и служи за еталон при оценка на практическите решения. Практическият минимум (близък до оптимума) се определя чрез емпирично измерване и сравнение на реални алгоритми с теорията.
Често използвани алгоритми за изхвърляне
- LRU (Least Recently Used) – „най-малко последно използваните“: изтриват се елементите, които не са били използвани най-дълго. LRU се имплементира практически чрез свързване на хеш-таблица с двусвързан списък (hash + doubly linked list), което дава O(1) за достъп, вмъкване и изтриване. Реализациите за хардуер (или при ограничени ресурси) използват приближени техники като CLOCK или битови „възрастови“ полета. LRU е удобно и често добра вибрация, когато натоварването показва силна времева локалност. LRU също е семейство от алгоритми, включващо вариации като 2Q и LRU-K (за по-добро разграничение на еднократни пикови достъпи).
- MRU (Most Recently Used) – „най-скоро използваните“: първо се премахват най-скоро използваните елементи. MRU може да е полезен при специфични патерни на достъп, например когато данните, които току-що са били достъпени, е вероятно да не бъдат повторно използвани скоро (например при някои видове сканиращи работни натоварвания). MRU се среща и в някои кешове за памет на бази данни.
- PLRU (Pseudo-LRU): приближение на LRU, което изисква малко по-малко информация. Често се използва в хардуерни кешове, където се налага да се ползва само по един бит на елемент или малко повече (например дървовидна PLRU за 4- или 8- начини асоциативни кешове). PLRU не гарантира точно LRU поведение, но обикновено изхвърля „един от“ най-старите елементи с по-ниска цена за поддръжка.
- LFU (Least Frequently Used) – „най-рядко използваните“: следи колко пъти е използван всеки елемент и премахва тези с най-ниска честота. LFU е подходящ при натоварвания с постоянни „горещи“ обекти, но може да „запуши“ кеша с елементи, които са били използвани често в миналото, но вече не са нужни. Практични имплементации използват „изглаждане“ или периодично спадане (decay) на броячите, за да решат този проблем.
- ARC (Adaptive Replacement Cache): баланс между LRU и LFU чрез адаптивно управление на две структури (списъци) за скорошни и чести елементи и две истории (history lists), които помагат да се настрои дялът на кеша между тях динамично. ARC се адаптира към работното натоварване, като автоматично премества капацитета между „recency“ и „frequency“ групите, за да подобри общия hit rate.
- MQ (Multi-Queue) – алгоритъм в няколко опашки: (от Y. Zhou, J.F. Philbin и Kai Li) използва множество опашки (нива), чрез които елементите „преминават“ според честота и скорошност. Така се постига добра изолация между еднократни и често използвани обекти и намалява замърсяването на кеша.
Ассоциативност и хардуерни варианти
- 2-пътен асоциативен кеш (2-way set-associative): адресът на даден елемент се мапва към набор (set), в който има две възможни места (lines). При конфликт LRU (или еквивалентна политика) премахва една от двете. Изисква по един бит на двойка, за да се посочи предпочитана линия при PLRU-приближения.
- Direct-mapped cache: най-бързият вариант за процесорни кешове — всеки адрес има точно едно място. Всичко, което вече е там, се изхвърля при вмъкване. Това минимизира хардуерната сложност, но повишава вероятността от конфликти.
Практически аспекти и оптимизации
- Структури и сложност: добрата LRU имплементация използва хеш + двусвързан списък за O(1) операции; LFU изисква поддръжка на броячи (може да е по-скъпо), ARC и MQ използват повече памет за мета-данни.
- Адаптация и decay: LFU често се подобрява чрез периодично намаляване на броячите (aging), за да се избегне „вечен“ кеш на остарели популярни елементи.
- Костове на елементите: кешът може да предпочете да запази „скъпи“ за възстановяване елементи (с високо време за изтегляне или изчисление) и да изхвърля евтини елементи първо.
- Различни размери на елементите: ако елементите имат различни размери, може да е по-добре да се избегне проста политика „един елемент = една единица“. Стратегии като size-aware eviction (например, LRU с икономика на размер) позволяват да се освободи място за няколко малки елемента вместо един голям.
- Срок на годност (TTL): кешове като DNS, браузърни кешове или кешове за новинарски агрегатори често имат ограничен живот (TTL). Когато TTL изтече, елементът се счита за невалиден и може да се премахне автоматично, намалявайки нуждата от сложни стратегии за изхвърляне.
- Политики за запис (write policies): write-through vs write-back и допълнителни техники (write allocate, no-write allocate) влияят на производителността и сложността на консистентността.
- Admission и bypass: не всички вмъквания в кеша водят до задължително вмъкване — някои системи прилагат политики за тестване (например, предварителна проба), за да предотвратят „внасяне“ на еднократни обекти, които ще замърсят кеша.
Сравнение и избор на алгоритъм
Изборът на алгоритъм зависи от характерните свойства на натоварването:
- Ако доминира силна времева локалност — LRU (или приближения) обикновено е най-добрият избор.
- При устойчиви „горещи“ обекти, които не се менят често — LFU (или хибрид като ARC) може да даде по-добър резултат.
- Ако имате ограничени ресурси за мета-данни (хардуерни кешове), PLRU или direct-mapped могат да са подходящи.
- ARC и MQ са добри, когато натоварването се променя динамично и е трудно да се предвиди дали преобладава честота или скорошност.
При практическа оценка винаги измервайте действителния hit rate, латентност на misses (miss penalty), CPU и паметни разходи за мета-данни, и влиянието върху съответните работни потоци.
Кохерентност на кеша
Съществуват и различни алгоритми за поддържане на кохерентността на кеша. Това се отнася за системи с множествo независими кеша, които съдържат една и съща логическа информация (например няколко сървъра или множество нива на кеш в многоядрени процесори). Политики като MESI/MOESI, write-invalidate и write-update определят как и кога промени в един кеш се отразяват в другите, за да се гарантира коректност.
Кратки препоръки
- Започнете с проста LRU имплементация (или CLOCK за по-малко ресурсоемки сценарии) и измервайте.
- Ако откриете, че едни и същи обекти остават „горещи“ за дълго време, помислете за LFU или ARC.
- При хардуерни или много-бързи кешове изберете приближени методи (PLRU, direct-mapped, set-associative) заради ниската латентност.
- Винаги профилирайте конкретното приложение — универсално „най-добър“ решение няма; работното натоварване диктува оптималната политика.

Въпроси и отговори
В: Какво представлява алгоритъмът на кеша?
О: Алгоритъмът на кеша е алгоритъм, който се използва за управление на кеш или група данни. Той решава кой елемент трябва да бъде изтрит от кеша, когато той е пълен.
В: Какво е коефициент на попадане?
О: Честотата на попаденията описва колко често дадена заявка може да бъде обслужвана от кеша.
В: Какво описва латентността?
О: Латентността описва за колко време може да се получи даден елемент от кеша.
В: Какво представлява оптималният алгоритъм на Белади?
О: Оптималният алгоритъм на Белади, известен още като алгоритъм на ясновидеца, е ефективен алгоритъм за кеширане, който винаги изхвърля информацията, която няма да бъде необходима за най-дълъг период от време в бъдеще. Този резултат обикновено не може да бъде приложен на практика, тъй като изисква да се предвиди какво ще бъде необходимо далеч в бъдещето.
Въпрос: Как работи принципът за най-рядко използвана информация (LRU)?
О: LRU първо изтрива най-малко използваните елементи и изисква да се следи какво е било използвано кога, като се използват "бита за възраст" за всяка кеш-линия и се проследява коя от тях е била най-малко използвана въз основа на битите за възраст. Всеки път, когато се използва кеш-линия, възрастта на всички други кеш-линии се променя съответно.
Въпрос: Как функционира функцията за най-скорошно използване (MRU)?
О: MRU изтрива най-наскоро използваните елементи първи и този механизъм за кеширане обикновено се използва за кешове на паметта на бази данни.
В: Какви други алгоритми съществуват за поддържане на кохерентността на кеша?
О; Съществуват различни алгоритми за поддържане на кохерентност на кеша, когато се използват множество независими кешове за споделени данни, като например множество сървъри на бази данни, които актуализират един общ файл с данни.
Свързани статии
Автор
AlegsaOnline.com Кеширане и алгоритми за изхвърляне: LRU, LFU, ARC, принципи и сравнение Leandro Alegsa
URL: https://bg.alegsaonline.com/art/15882
Източници
- usenix.org : usenix.org/legacy/events/fast03/tech/full_papers/megiddo/megiddo.pdf
- usenix.org : usenix.org